Code Generation Toolkit
The object of CG-Kit is to empower knowledgeable users to be able to express their desired execution control flow and the map of what to compute where in a recipe without having to change the source code. Our vision is to provide a shorthand for expressing the needed variations in implementation that enable optimization of the application instance as desired. With CG-Kit the variants can be expressed succinctly in Python without including any of the data layout and numerical detail. The recipes are parsed and coverted into graphs which are optimized for minimizing data movement and maximizing data reuse and potential for latency hiding. Optimized graphs are then converted to parameterized source trees (PST) that serve the same purpose for code generation in compilable langagues as abstract syntax trees (AST) do for compiling a code into an executable. The ASTs have rich context information that can be utilized for code transformation without user intervention. In the context of algorithmic variants, we would like to shift implementation efforts to controlling code generation tools instead of directly working with the code. We achieve this by decomposition of source code into templates that are user-defined blocks of source code. Platform-dependent customizations are encapsulated in the templates using macros (to be described later). The PSTs are constructed from these code templates. The final generated code is compilable and optimized for readability by human programmers, which is a key property to aide developers with code understanding, debugging, and reasoning about performance metrics.
Patterns
There are recurring patterns that are recognized by the CG-Kit recipe interface. These are:
#. Pipeline A pipeline expresses the execution order of code generation operations and the dependencies of operations on one another. If operations are meant to be applied to data items (e.g., discretized spatial/temporal operators of a partial differential equation), then those data items would flow through the pipeline concurrently; hence, the data items are assumed to be independent of each other.
#. Begin-End A begin-end pattern describes the nesting of code generation operations (and/or a pipeline of operations) within a construct that has a defined beginning and an end, for example, a loop or a conditional statement. The coupling of a pair of begin-end nodes enables initialization and finalization of code generation tasks as these nodes are visited in the order of their occurrence in the graph.
#. Concurrent Data The concurrent data pattern describes a single operation or a pipeline of operations executed on independent data items. This pattern is derived from the begin-end pattern; thus, implementing the concurrent data pattern involves a pair of begin and end nodes. The relevance of having this pattern is to enable expressing data parallelism in a code generation workflow.
The motivation for recipes is to enable users to abstract building blocks of algorithms to a desired level such that variants can be easily composed and modified. The particular level or degree at which an algorithm’s implementation is abstracted will strongly depend on the algorithm itself. Therefore, CG-Kit recipes do not make assumptions about the abstraction, instead, they let the users define the level of desired abstraction. Recipes follow a ``define and run’’ principle. This principle entails that the recipe writer selects the granulariy of algorithmic building blocks (e.g., subroutines, actions, etc.) and defines their dependencies on each other.
Example
We have applied CG-Kit to generate variants in the new Hydro solver, Spark, which has two different modes for optimizing memory and communication optizations. The memory optimizations apply to using Spark with AMReX, which prefers to apply flux-correction on a per level basis and allocate and deallocate memory for storage of fluxes at that level before going on to the next finer level. Paramesh applies flux-correction at all levels simultaneously. In principle this can be done for AMReX too by keeping the flux-storage around until all levels have finished computing. The communication optimization at the cost of extra computation and memory applies to multi-stage RK integration. The telescoping mode of operation gets extra layers of guardcells and in all except the final stage also updates the cells that will act as guardcells for the next stage. Thus for a 2 stage RK we get 2*NGUARD guardcells along each face In the first stage we update NGUARD extra cells along each face so that no communication is requered to fetch them from neighboring blocks. The figure below shows two of these variants.
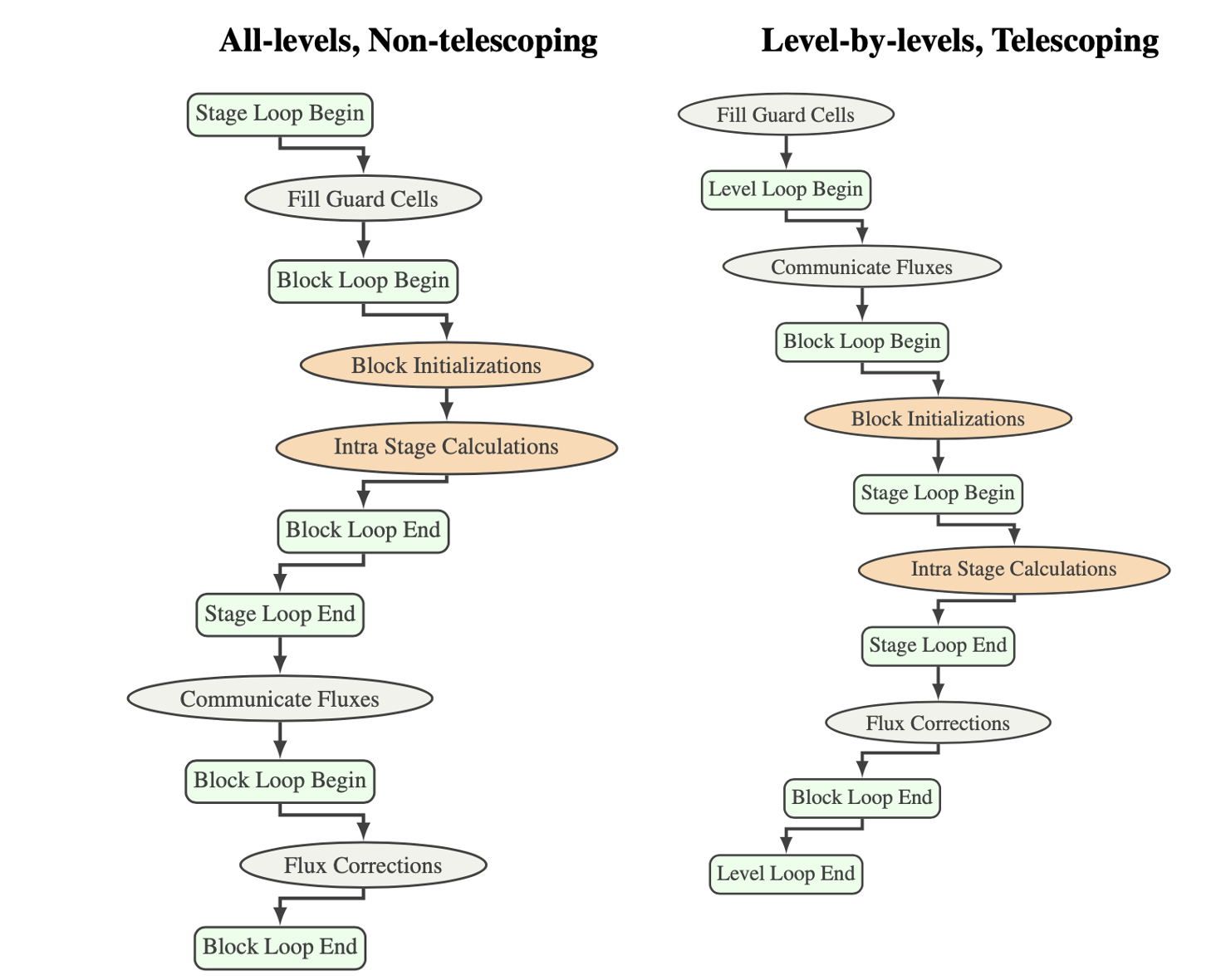
In these variants the arithmetic of physics computations remains unchanged, the only difference occur in the control flow of the algorithm and where communications are placed during computation. Recipes provide a succint way of expressing these variants.