Milhoja
Milhoja is a domain specific runtime design to execute a graph given to it over and over again. The motivation comes from the kind of applications that have an evolution cycle where the control flow does not vary from one timestep to another, but might vary from one application instance to another. Thus all the analysis for optimizing the graph is done offline. Milhoja does not concern itself with concepts such as work stealing, or reapportioning work dynamically. In that sense it an execution engine that makes the data and the computation move as dictated by user’s recipe translated by CG-Kit into a graph.
Milhoja Design Features
The design goal of Milhoja is to develop a base set of runtime elements, such as thread teams, that can be composed at runtime into thread team configurations in ways that maximize the efficient use of the node. For a given simulation, Milhoja operates with \(N\) thread teams that are created when the simulation starts and persist until the simulation terminates, where each team is allowed to simultaneously use at most \(M\) threads at any given time. The thread teams are run in cycles such that for each cycle a team is assigned an action routine and a data model. Examples of data model are tiles, blocks, and data packets of blocks. Upon starting a cycle, the team is given the data and the threads of the team work in a coordinated fashion so that the given action is applied to each data item once. The cycle ends once the team has been informed that no more data items will be given and the action has been applied to all given data items. In our design, the pairing of the action with data items is viewed as a task so that thread teams implement task-based parallelism via thread-level parallelism. While the threads in the team execute code in the host, they can also be used to launch kernels in accelerators and therefore make use of finer-grained parallelism. Ideally, the data type assigned to a thread team for a given action will be chosen based on the hardware that the action routine has been written to use. For instance, a tile would be a sensible data type for executing an action routine that uses the CPU for heavy computation or a data packet of blocks for a routine that launches kernels on a remote device with its own memory system.
Note that no part of this design limits itself to using manually built task graphs nor requires extreme simplicity in them. The interfaces are designed to be robust enough that Milhoja can also execute complex task graphs. By ddisassociating the executor of the graph from the generator, we have ensured that in the future, we will be able to use automation in task graph generation without having to alter the mechanics of the Milhoja. All the heavy lifting of analysis and scheduling can be done separately in the generator which never needs to interface with the executor. We believe that this model of combination of program synthesis with orthogonal composition concepts will have longevity because of its ability to adapt to new systems incrementally.
Milhoja relies upon helper code generation tools to perform its work. Given that the task definition can vary from one application instance from another even when the underlying physics is unvarying, clearly the data and computation that needs to move between devices is not known apriori. That information is generated by CG-Kit. Therefore we need code generators that can create data packets and tasks to be digested by Milhoja based upon the recipe that is ingested by CG-Kit. Note that if there is no division of work between devices in the recipes CG-Kit, Milhoja need not be used in the application at all, and CG-Kit is able to generate all the needed code. However, if Milhoja is to be used, then these additional code generators come into play.
The code generator for assembling data packets relies upon annotations in the interfaces of the unit API. In Flash-X every unit has a file that specifies all of the unit’s public interfaces. We include comments in the interface file that describe all of the information needed by the code generators for data packets and tasks. An example of these annotations is given below
insert the comment section of hydro
Note that the annotations start by defining data and arguments that are common to more than one interface to avoid having to replicate the definitions. Each of the data items is accompanied by the information that tells its size to the data packet generator. Additional information that is critical for data packet generator is whether the data item needs to move back and forth from the host to device and vice versa or if it is strictly temporary – it needs to have space on the device but never needs to move between devices. A parser converts this information into json files that the code generators can use to emit data for both data packet and task generation.
Runtime Elements
The primary runtime elements are the thread teams which are created on the host when the simulation starts and persist throughout the application execution. The number of threads in each team is specified at the time of execution. To apply a computation to a set of blocks in an arbitrary order, a thread team is assigned an associated taskfunction along with all relevant data. items get enqueued with the thread team for execution. Milhoja coordinates the asynchronous movement of data to the target memory systems as well as execution of all associated tasks. Note that taskfunctions can execute code on any device without being aware of the specifics of the device so long as the required data is resident in the appropriate memory system.
Runtime Examples
Below are the examples of possible thread team configurations in increasing order of complexity.
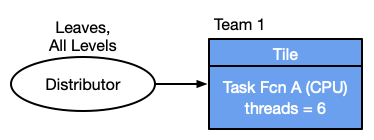
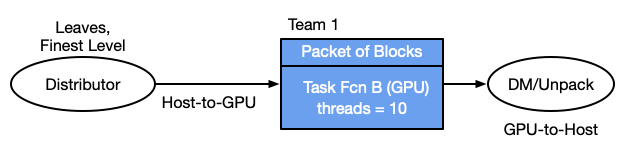
The figure above shows a configuration where computation is being done only on the CPU, while the next figure shows computation only on the GPU. Note that there are addiotional steps of data packing and unpacking and the data is moving back and forth between the host and the GPU.
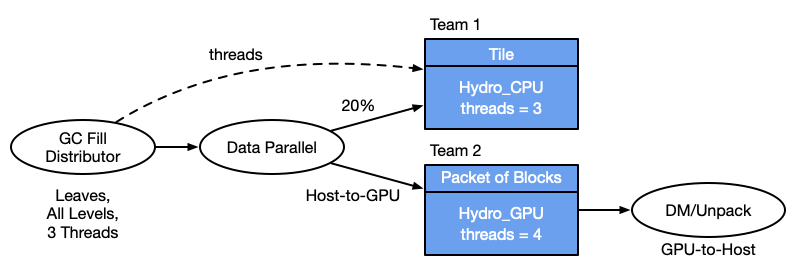
The next figure shows a configuration with the next level of complexity where both CPU and GPU are applied to the same task. Two teams are in operation, the CPU team is given 3 thread and the GPU team is given 4 threads. These threads are used only for moving data, not for computation.
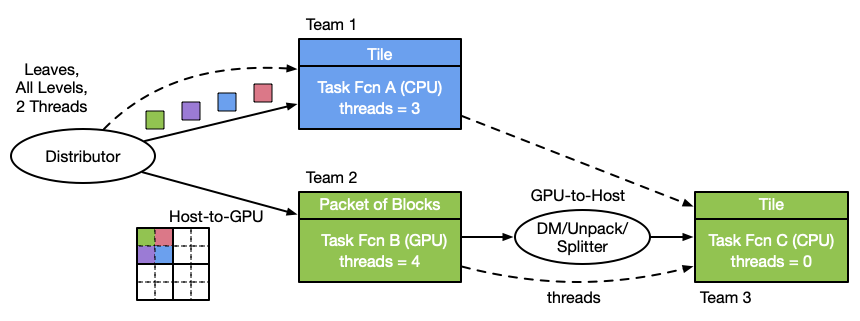
The final figure shows an example of how we envision Milhoja being used. Here concurrent computations are proceeding on the two devices but they are allotted different tasks at first. The data from GPU is sent back to the CPU once its computation is done, and yet another task is performed on the CPU.
>>>>>>> main